
How I use AI to extract structured data like JSON/ YML from Images?
Recently I incountered a very boring task which should be automated up until now. The task is very simple I have a Image of a question with multiple options I have to convert it into a JSON file format to further process it. The task is very simple yet If I have to do it for 10 question each day for next 6 months I should automate this.
So if you are a tech geek like me you may have already figured out the solution. OCR It is.
But Here is the problem begins, so in traditional OCR you can easly extract the text but can’t get in a schema like JSON. adding to that every image has different dimention, apsect ratio, poisiton of the question.
Using LLM to extract and format text
The solution is quite simple, using LVLM(Large Vision Language Model) to extract and format the text. So how this stratgy should work? There are a special type of Multimodel LLMs like LVLMs. They can take both formates like text, image as input and give text as output.
Here is List of LVLM’s As of now
- InstructBLIP
- MiniGPT-4
- Gemini Pro
- LLaVA
- Qwen-VL
Step 1: Lets try out a demo
For this demo you can goto https://llava.hliu.cc
Here in the UI we have give the question image and then the prompt mention below
Extract text from the image and print it in the below format. For the question and options remove any prefix like a, b, c or 1, 2, 3 etc.
Format:
{
"id": "00",
"question": "{question}",
"options": [
"{option 1}",
"{option 2}",
"{option 3}",
"{option 4}"
],
"answer": "{option index in number if unknown then 0}",
"tags": [
"psychology"
]
}It will look something like this.
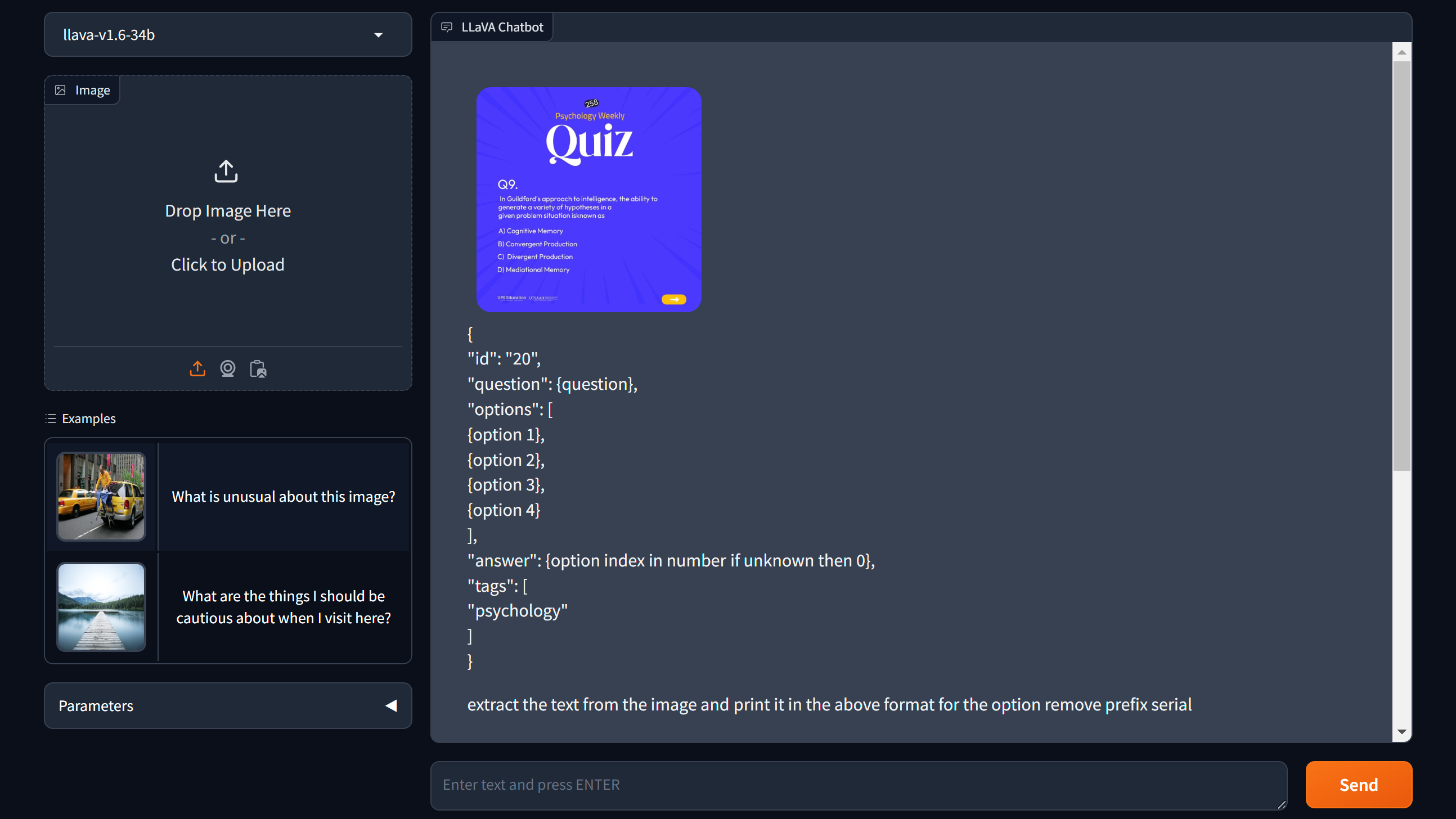
After hitting send button we will get our output. which will look something like this. You can use also Gemini for this case
Output
{
"id": "20",
"question": "In Guildord's approach to intelligence, the ability to generate a variety of hypotheses in a given problem situation is known as",
"options": ["Cognitive Memory", "Convergent Production", "Divergent Production", "Mediational Memory"],
"answer": 3,
"tags": ["psychology"]
}Step 2: Use LLavA API
The web response is fine but still we have one issue.
- I want end to end automated solution. So I can’t upload, send and extract for each images.
We can reverse engineer the api calls and figure out whats going on under the hood. Here is the summary
baseURL = https://llava.hliu.cc
Upload Image
POST /upload?upload_id=8mw3dxwtghj input -> body form data file output -> file path
Check Upload Progess (optional)
GET /upload_progress?upload_id=8mw3dxwtghj output -> {“msg”: “done”}
Add The prompt with the image path
POST /queue/join?
{
"data": [
null,
"what is the document in two word",
{
"path": "/nobackup/haotian/tmp/gradio/4b3f249dd60fab9dcf361035bb95cfb9ed680bf4/Expenses Tracker.jpg",
"url": "https://llava.hliu.cc/file=/nobackup/haotian/tmp/gradio 4b3f249dd60fab9dcf361035bb95cfb9ed680bf4/Expenses Tracker.jpg",
"orig_name": "Expenses Tracker.jpg"
},
"Default"
],
"fn_index": 9,
"session_hash": "ec2walcbadh"
}Add the parameters
POST /queue/join?
{
"data": [null, "llava-v1.6-34b", 0.1, 1.0, 256],
"fn_index": 10,
"session_hash": "ec2walcbadh"
}Get the response
GET /queue/data?session_hash=ec2walcbadh
{
"msg": "process_completed",
"output": {
"data": [null, [["", "Expense tracker"]]],
"is_generating": true,
"duration": 0.12835431098937988,
"average_duration": 0.7358614400381713
},
"success": true
}Step 3: Use LLaVA locally using OLLaMa
- If I am not connected to internet I can’t use that
- I don’t want to share my images over internet for privacy reasons
Here also the steps are very simple. First goto https://ollama.com. Download ollama and install on your system. To check it everything working goto http://localhost:11434 and you will see “Ollama is running”.
Now using your terminal run this commend
ollama run llava
this commend will pull the model so it will take some time depending on the network bandwidth.
Writing a Simple Script
After this we have to write a simple script which can interact with the api which is exposed by ollama. In this step we can use Offical Libraries by ollama. Here we will use the python library.
First we will create a virutal enviroment. Then
pip install ollama
import ollama
import base64
import json
prompt = "Extract text from the image and print it in the below format. For the question and options remove any prefix like a, b, c or 1, 2, 3 etc \n\nFormat: " + str({
"question": "{question}",
"options": [
"{option 1}",
"{option 2}",
"{option 3}",
"{option 4}"
],
"answer": "{option index in number if unknown then 0}",
"tags": [
"psychology"
]
})
print("\nPrompt:\n" + prompt)
input_file_name = "questions-1"
encoded_image = ""
with open(f"./images/{input_file_name}.jpg", "rb") as json_file:
encoded_image = str(base64.b64encode(json_file.read()))[2:-1]
response = ollama.generate(model='llava',
prompt=prompt,
images=[encoded_image],
format='json',
stream=False)
print(response['response'])
with open(f"./data/{input_file_name}.json", "w") as json_file:
json_file.write(response['response'])the code is simple here I am opening a image and converting it into base64 encoding and giving the previous prompt. Now using ollama library we are sending the request to the ollama api. Now after getting the response I am saving it into a json file.
Here is the output.
{
"id": "20",
"question": "Q9",
"options": ["The process by which a neutral stimulus becomes associated with a conditioned response is known as:", "a) Generalization", "b) Discrimination", "c) Extinction", "d) Acquisition"],
"answer": "3",
"tags": ["psychology"]
}Here you can see the response it a little bit messed up.
Adding Example for Onshot Learning
So I give a example input image and example output json. The code will look something like this.
import ollama
import base64
import json
example_input_image = ""
example_output_json = ""
with open("./example/input.jpg", "rb") as json_file:
example_input_image = str(base64.b64encode(json_file.read()))[2:-1]
with open("./example/output.json", "rb") as json_file:
example_output_json = str(json.load(json_file))
prompt = "Extract text from the image and print it in the below format. For the question and options remove any prefix like a, b, c or 1, 2, 3 etc \n\nFormat: " + str({
"question": "{question}",
"options": [
"{option 1}",
"{option 2}",
"{option 3}",
"{option 4}"
],
"answer": "{option index in number if unknown then 0}",
"tags": [
"psychology"
]
}) + "\n\nHere is an example the first image is the example input image the example output should be\n\n" + example_output_json + "\n\nNow give the output of 2nd by processing 2nd image"
print("\nPrompt:\n" + prompt)
input_file_name = f"questions-{i}"
encoded_image = ""
with open(f"./images/{input_file_name}.jpg", "rb") as json_file:
encoded_image = str(base64.b64encode(json_file.read()))[2:-1]
response = ollama.generate(model='llava',
prompt=prompt,
images=[example_input_image, encoded_image],
format='json',
stream=False)
print(response['response'])
with open(f"./data/{input_file_name}.json", "w") as json_file:
json_file.write(response['response'])The base code is same we just added example_input_image and example_input_json and modified the prompt a little bit
Here is the output.
{
"id": "20",
"question": "Q9",
"options": ["The process by which a neutral stimulus becomes associated with a conditioned response is known as:", "a) Generalization", "b) Discrimination", "c) Extinction", "d) Acquisition"],
"answer": "3",
"tags": ["psychology"]
}as you can see the output is a little bit better
to ensure the best performance installed the 13B model for LLaVa.
ollama run llava:13b
Here is the final code
import ollama
import base64
import json
example_input_image = ""
example_output_json = ""
with open("./example/input.jpg", "rb") as json_file:
example_input_image = str(base64.b64encode(json_file.read()))[2:-1]
with open("./example/output.json", "rb") as json_file:
example_output_json = str(json.load(json_file))
prompt = "Extract text from the image and print it in the below format. For the question and options remove any prefix like a, b, c or 1, 2, 3 etc \n\nFormat: " + str({
"question": "{question}",
"options": [
"{option 1}",
"{option 2}",
"{option 3}",
"{option 4}"
],
"answer": "{option index in number if unknown then 0}",
"tags": [
"psychology"
]
}) + "\n\nHere is an example the first image is the example input image the example output should be\n\n" + example_output_json + "\n\nNow give the output of 2nd by processing 2nd image"
print("\nPrompt:\n" + prompt)
totalResponse = ""
for i in range(1,11):
input_file_name = f"questions-{i}"
encoded_image = ""
with open(f"./images/{input_file_name}.jpg", "rb") as json_file:
encoded_image = str(base64.b64encode(json_file.read()))[2:-1]
response = ollama.generate(model='llava:13b',
prompt=prompt,
images=[example_input_image, encoded_image],
format='json',
stream=False)
print(response['response'])
totalResponse += response['response']
with open(f"./data/{input_file_name}.json", "w") as json_file:
json_file.write(response['response'])
with open(f"./data/total.json", "w") as json_file:
json_file.write(totalResponse)for the code part you have to change just
model=‘llava’ -> model=‘llava:13b’
added a for loop for iterate over multiple images
Here is the final output
[
{
"question": "The ability of the human mind to generate hypotheses in a variety of problem situations given only that they are known as",
"options": ["Cognitive Memory", "Convergent Production", "Divergent Production", "Mediation"],
"answer": 3,
"tags": ["psychology"]
}
]Summery
Here are some pros and cons of this strategy
Pros
Cons
Resources
Feedback
Give us Feedback by directly mailing us. Also If you spot any mistake in the post reach us via email at [email protected]. And if you have a topic in your mind about AI feel free to reach us, we will be happy to respond you.